
一 概述
1 kafka特点
Kafka 最早是由 LinkedIn 公司开发一种分布式的基于发布/订阅的消息系统,之后成为 Apache 的顶级项目。主要特点如下:
1.1 同时为发布和订阅提供高吞吐量
Kafka 的设计目标是以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对TB 级以上数据也能保证常数时间的访问性能。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条消息的传输。
1.2 消息持久化
将消息持久化到磁盘,因此可用于批量消费,例如 ETL 以及实时应用程序。通过将数据持久化到硬盘以及 replication 防止数据丢失。
1.3 分布式
支持 Server 间的消息分区及分布式消费,同时保证每个 partition 内的消息顺序传输。这样易于向外扩展,所有的producer、broker 和 consumer 都会有多个,均为分布式的。无需停机即可扩展机器。
1.4 消费消息采用pull模式
消息被处理的状态是在 consumer 端维护,而不是由 server 端维护,broker 无状态,consumer 自己保存 offset。
1.5 支持online和offline的场景。
同时支持离线数据处理和实时数据处理。
2 Kafka 中的基本概念

2.1 Broker
Kafka 集群中的一台或多台服务器统称为 Broker
2.2 Topic
每条发布到 Kafka 的消息都有一个类别,这个类别被称为 Topic 。(物理上不同 Topic 的消息分开存储。逻辑上一个 Topic 的消息虽然保存于一个或多个broker上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)
2.3 Partition
Topic 物理上的分组,一个 Topic 可以分为多个 Partition ,每个 Partition 是一个有序的队列。Partition 中的每条消息都会被分配一个有序的 id(offset)
2.4 Producer
消息和数据的生产者,可以理解为往 Kafka 发消息的客户端
2.5 Consumer
消息和数据的消费者,可以理解为从 Kafka 取消息的客户端
2.6 Consumer Group
每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定Group Name,若不指定 Group Name 则属于默认的 Group)。 这是 Kafka 用来实现一个 Topic 消息的广播(发给所有的 Consumer )和单播(发给任意一个 Consumer )的手段。一个 Topic 可以有多个 Consumer Group。Topic 的消息会复制(不是真的复制,是概念上的)到所有的 Consumer Group,但每个 Consumer Group 只会把消息发给该 Consumer Group 中的一个 Consumer。如果要实现广播,只要每个 Consumer 有一个独立的 Consumer Group 就可以了。如果要实现单播只要所有的 Consumer 在同一个 Consumer Group 。用 Consumer Group 还可以将 Consumer 进行自由的分组而不需要多次发送消息到不同的 Topic 。
二 单机部署
1 安装ZooKeeper
参考芋道 Zookeeper 极简入门 | 芋道源码 —— 纯源码解析博客 (iocoder.cn)
2 安装kafka
2.1 下载软件包
打开 Kafka Download 页面,我们可以看到 Kafka 所有的发布版本。这里,我们选择最新的 Kafka 2.3.1 版本。这里,我们可以看到两种发布版本:
- Source: kafka-2.3.1-src.tgz
- Binary: kafka_2.12-2.3.1.tgz
一般情况下,我们可以直接使用 Binary 版本,它是 Kafka 已经编译好,可以直接使用的 Kafka 软件包。
下面,我们开始下载 Kafka Binary 软件包。命令行操作如下:
1 | # 下载 |
2.2 配置文件
在 config 目录下,提供了 Kafka 各个组件的配置文件。如下:
1 | $ ls -ls config |
这里,我们先创建一个 data 目录,然后编辑 conf/server.properties 配置文件,修改数据目录为新创建的 data 目录,即 log.dirs=/opt/kafka/kafka_2.12-3.3.1/data

修改一下kafka启动端口
- 内置zookeeper配置
1 | # The address the socket server listens on. It will get the value returned from |
- 修改server端口号,默认port没有写在文件中
1 | $ vim config/server.properties |
- 单机环境配置
1 | $ vim config/connect-standalone.properties |
- 集群环境配置
1 | $ vim config/connect-distributed.properties |
本地客户端配置,不用可以不修改。
- 消费端配置
1 | $ vim config/consumer.properties |
- 发布端配置修改
1 | $ vim config/producer.properties |
2.3 启动kafka
1 | nohup ./kafka-server-start.sh /opt/kafka/kafka_2.12-3.3.1/config/server.properties > /opt/kafka/kafka_2.12-3.3.1/logs/kafka.log 2>&1 & |
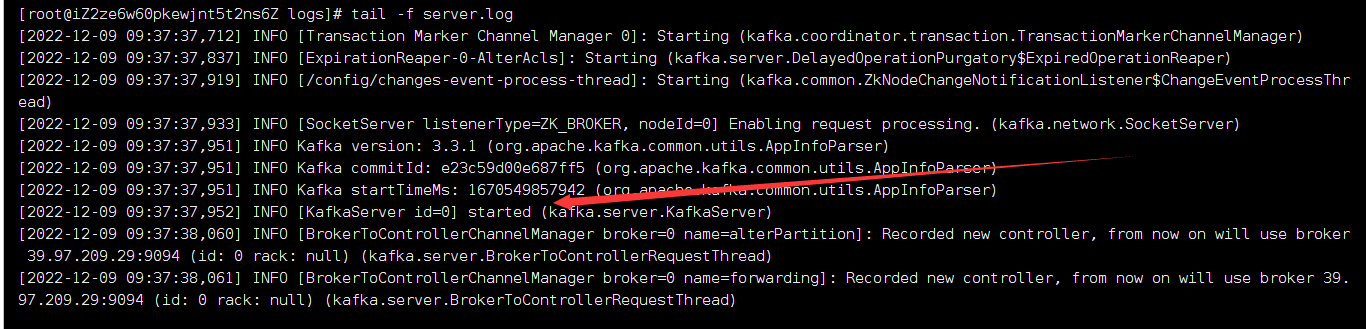
三 Kafka Manager
Kafka Manager改名成cmak了
3.1 下载解压软件包
1 | #下载 |
3.2 下载JDK11
下载JDK11不需要配置环境变量
3.3 修改配置
zookeeper是本地安装的所以修改为本地地址
1 | kafka-manager.zkhosts="127.0.0.1:2181" |
3.4 启动Kafka Manager
1 | nohup ./cmak -java-home /opt/kafka_manager/jdk11/jdk-11.0.17/ > /opt/kafka_manager/cmak-3.0.0.5/cmak.log 2>&1 & |
3.5 添加 Kafka 集群
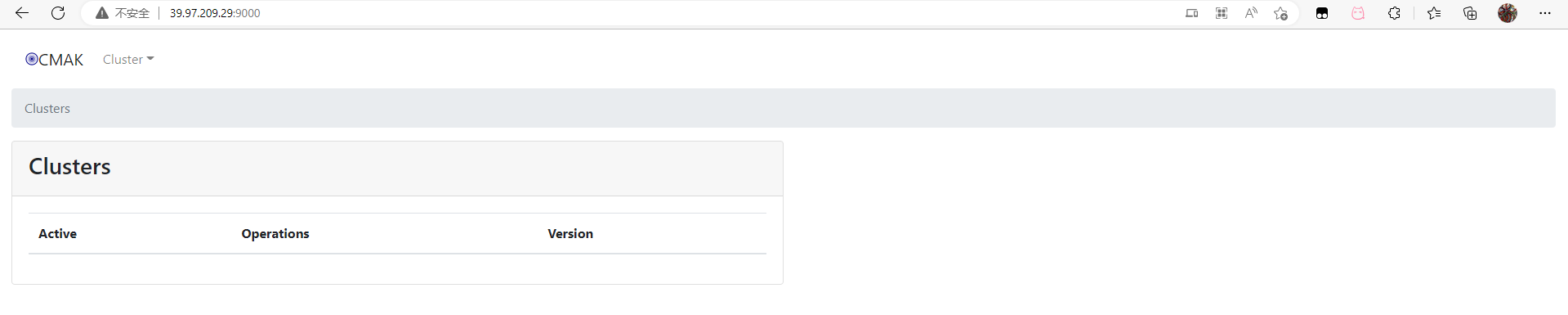
使用浏览器,访问 39.97.209.29:9000 地址,就可以看到 Kafka Manager 的界面。如下图:
点击导航栏的「Cluster」按钮,选择「Add Cluster」选项,在该界面,配置新增 Kafka 集群。如下图:

刷新页面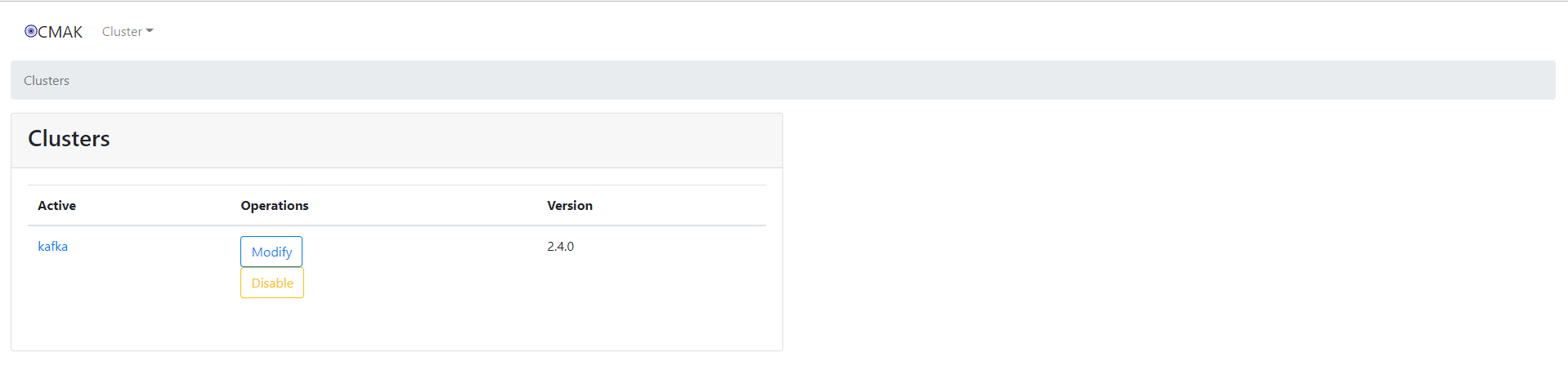
四 简单实例
4.2 依赖
1 | <!-- 引入 Kafka 客户端依赖 --> |
4.2 Producer
创建 ProducerMain 类,使用 KafkaProducer 发送消息。代码如下:
1 | public class ProducerMain { |
成功发送

4.2 Consumer
创建 ConsumerMain 类,使用 KafkaConsumer 消费消息。代码如下:
1 | // ConsumerMain.java |
可以看到成功消费
